一、String数据结构存放数据
1. String优点:
String可以保存二进制字节流,任何数据转换成二进制字节流就可以用String来存储,比较万金油;
2. 缺点:
String保存数据时占用的内存空间比其他数据结构更多(保存数据包含字符时底层使用SDS简单动态字符串);
3.为什么String类型会占用更多的空间
底层String类型的数据是怎么保存的:
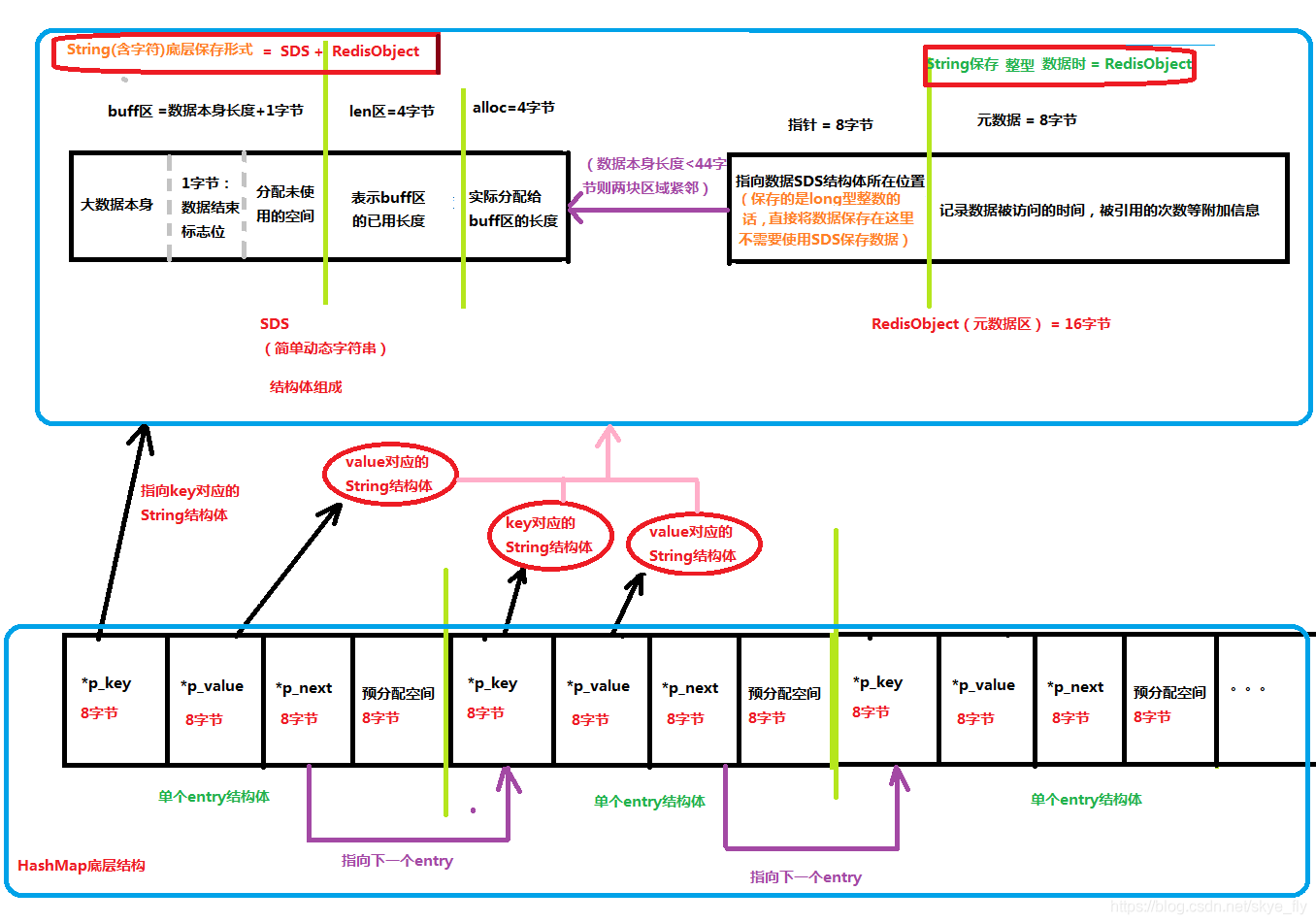
- 一个字符型String占用空间 =SDS结构体占用空间 +RedisObject元数据区占用空间 +HashMap的entry结构体占用空间;
- 一个int型String占用空间 =RedisObject元数据区占用空间 +HashMap的entry结构体占用空间。
SDS= buff + len + alloc
SDS除了要保存数据本身buff(结尾处有一个额外的字节表示数据结束),redis还会用其余一定字节数来保存对应该数据的其余信息(几个字节len表示该数据长度的buff、几个字节表示redis给该数据实际分配的空间大小alloc);
RedisObject元数据区:
元数据区用来记录该数据被访问的时间以及被引用的次数等额外信息。
HashMap的entry结构 = 指针 + 预分配空间
另外在考虑Redis的存储结构,底层是用HashMap存储的,那么HashMap的每一个entry结构体是怎么组成的呢?(三个8字节的指针 + 8字节预分配空间(因为为了减少操作次数redis只会分配2的幂次方大小的空间,就会有预留空间))
下面结合下图进行考虑:
假设Redis使用String的数据结构保存字符型数据,那么HashMap中的key和value底层都是String实现的,如下图所示,可以看出要保存一个值value,就需要考虑(HashMap中多出的三个指针 + 预分配空间)+(SDS结构体)+(RedisObject区),比数据本身会多出几十个字节,如果存储的数据本身只有几个字节,那么这些额外的字节就会占很大比重,(有种大马拉小车的感觉,浪费了马力强劲的发动机)
二、ziplist数据结构存放数据
为了节省内存空间,可以使用压缩列表来存储多个数据(存储集合类value(多个值)时):不然如果对于集合类value,一个key要对应多个String,那么在entry中要分别用一个指针指向一个集合中的元素,使用压缩列表的话,每个集合元素会在列表中依次紧邻放置,就不需要用一个单独的指针去寻找每个集合元素了,就可以用一个*p_value代替多个*p_value。
两者的对比如下图所示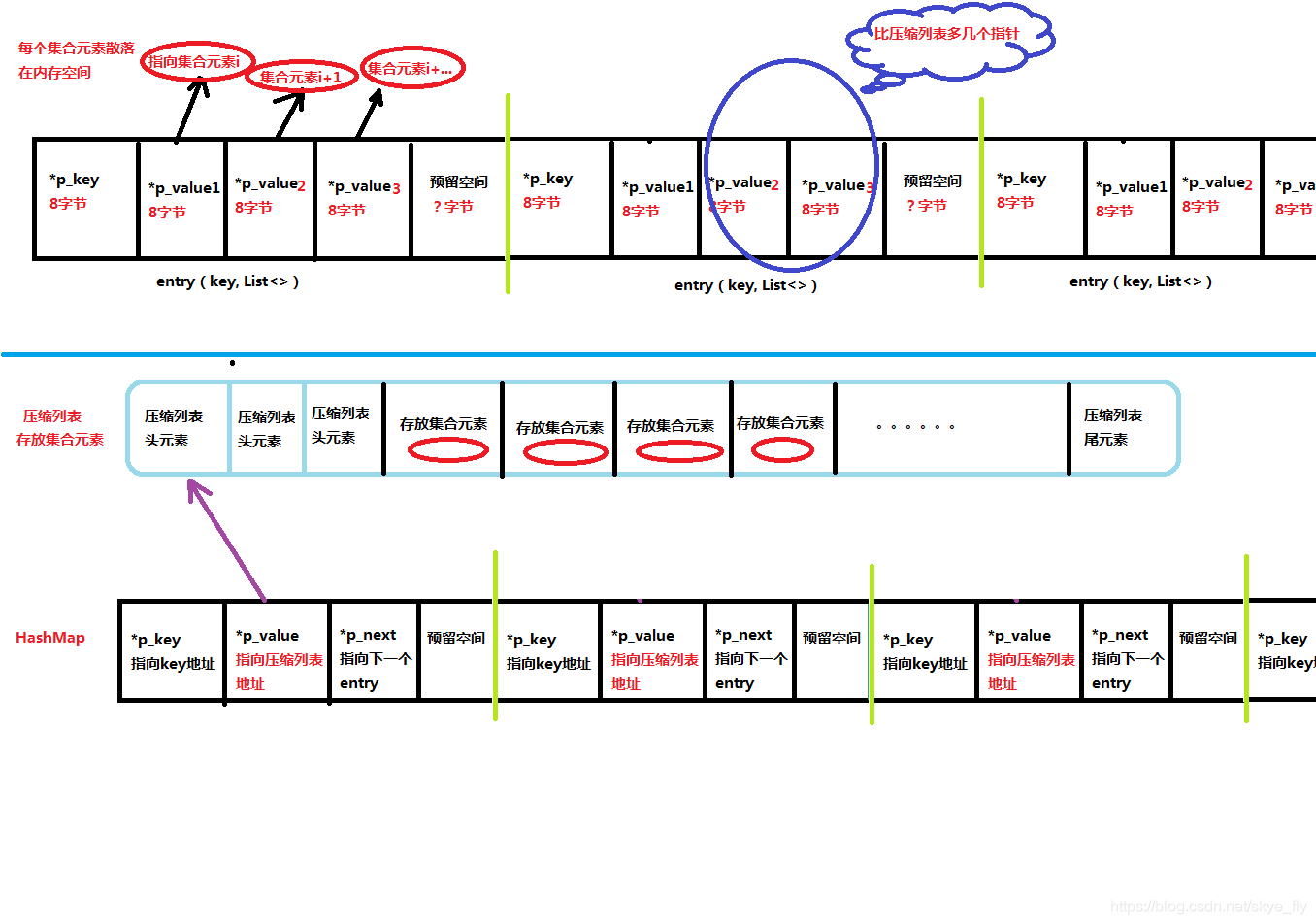
如上图所示,其实Redis底层会根据value对象的长度选择使用String还是使用压缩列表来存放,就算是一对一的(K,V)键值对当value长度短时也是使用压缩列表存放的,当value元素长度超过阈值时再转化为用String存放。
三、用zipList底层结构实现Hash数据结构
形象的拿Hash数据结构来说如何借助zipList节省内存空间
当HashMap中的Value存储的数据本身也是一个集合时,简单可以理解为Map中套Map,也就是(K,V)键值对中的Value也是一个Map。
拿用户的数据来说,外层Map的(K,V)保存的是用户id以及对应该id的用户的各种属性信息(phone:xxx, addr:xxx,age:xxx等),那么会有两种结构
- 一种是使用ZipList
- 另一种是使用HashTable(HashMap就是轻量级的HashMap)
数据长度短时使用ZipList时就如上文所说的可以节省内存空间,数据长度很大时则使用HashTable,更偏重于哈希的快速定位能力,两者对比图如下
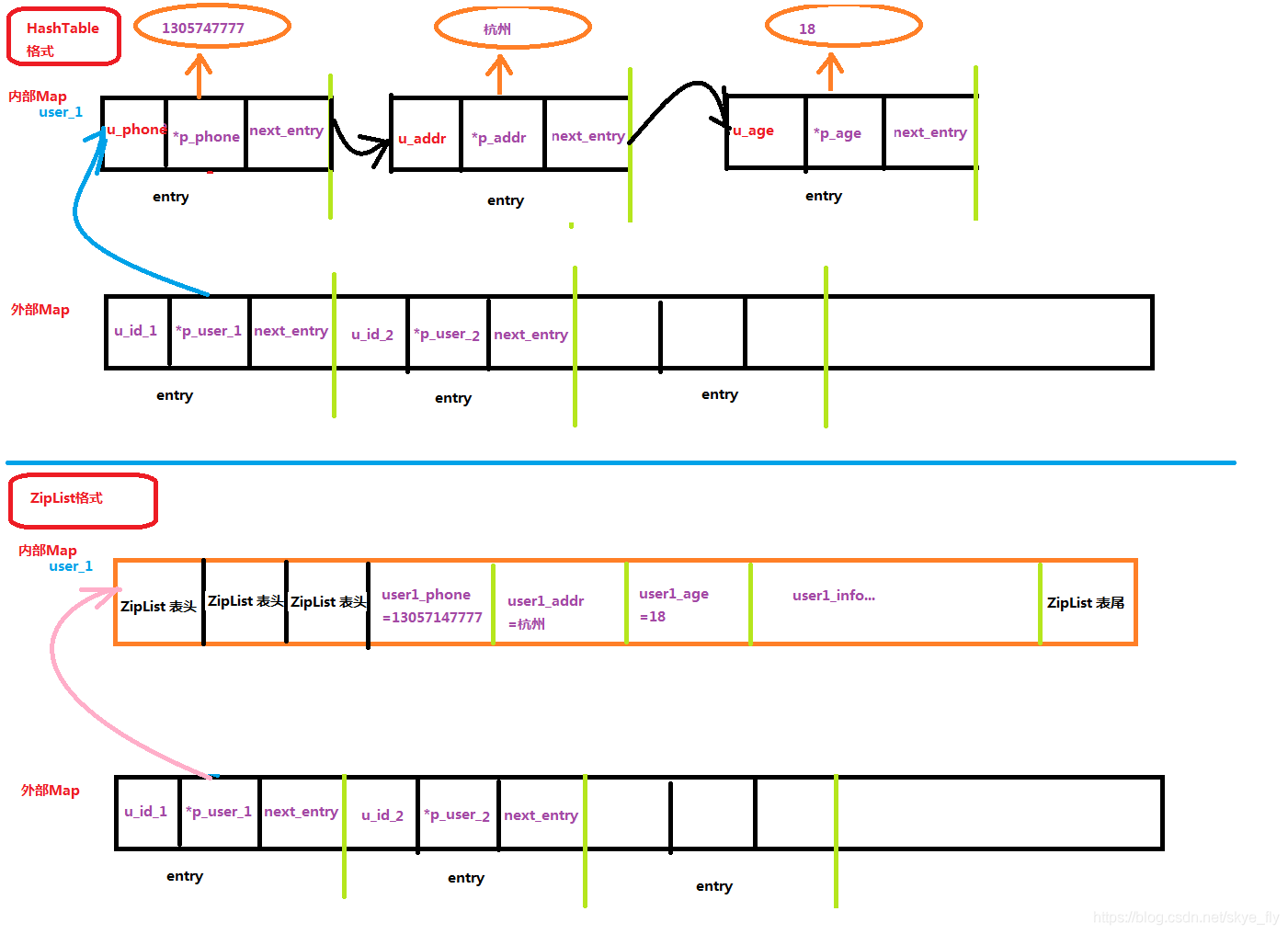
ps:使用压缩列表可以高效利用内存空间,但是查找元素时要在列表中遍历耗费时间,相对的,用一对一的存储方式可以直接根据hash表查询,速度更快,实际中要在内存占用和数据查询速度两者间平衡(空间换时间 or 时间换空间)。
参考文章:
https://time.geekbang.org/column/article/279649