本文为作者原创,未经允许不得擅自转载。
Excel是微软的经典之作,在日常工作中的数据整理、分析和可视化方面,有其独到的优势,尤其在你熟练应用了函数和数据透视等高级功能之后,Excel可以大幅度提高你的工作效率。但如果数据量超大,Excel的劣势也就随之而来,甚至因为内存溢出无法打开文件,后续的分析更是难上加难。那么,有什么更好的解决办法吗?工欲善其事,必先利其器,在这里我们介绍使用Python的pandas数据分析包来解决此问题。
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None,
usecols=None, squeeze=False,dtype=None, engine=None,
converters=None, true_values=None, false_values=None,
skiprows=None, nrows=None, na_values=None, parse_dates=False,
date_parser=None, thousands=None, comment=None, skipfooter=0,
convert_float=True, **kwds)pandas读取Excel后返回DataFrame,接下来我们就pd.read_excel()的常用参数进行详细解析。
目录
【文中使用英超、西甲的排名积分榜及射手榜作为原始数据~~~】
1、io,Excel的存储路径
- 建议使用英文路径以及英文命名方式。
import pandas as pd
io = r'C:\Users\Administrator\Desktop\data.xlsx'2、sheet_name,要读取的工作表名称
- 可以是整型数字、列表名或SheetN,也可以是上述三种组成的列表。
整型数字:目标sheet所在的位置,以0为起始,比如sheet_name = 1代表第2个工作表。
data = pd.read_excel(io, sheet_name = 1)
data.head()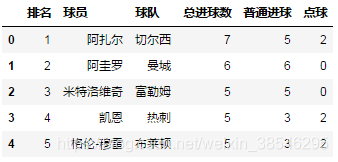
- 列表名:目标sheet的名称,中英文皆可。
data = pd.read_excel(io, sheet_name = '英超射手榜')
data.head()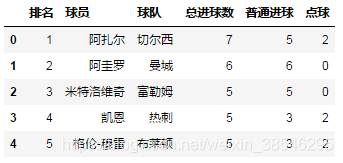
- SheetN:代表第N个sheet,S要大写,注意与整型数字的区别。
data = pd.read_excel(io, sheet_name = 'Sheet5')
data.head()
- 组合列表: sheet_name = [0, '英超射手榜', 'Sheet4'],代表读取三个工作表,分别为第1个工作表、名为“英超射手榜”的工作表和第4个工作表。显然,Sheet4未经重命名。
- sheet_name 默认为0,取Excel第一个工作表。如果读取多个工作表,则显示表格的字典。对于初学者而言,建议每次读取一个工作表,然后进行二次整合。
data = pd.read_excel(io, sheet_name = ['英超积分榜', '西甲积分榜'], nrows = 5)
# sheet_name = ['英超积分榜', '西甲积分榜'] ,返回两个工作表组成的字典
data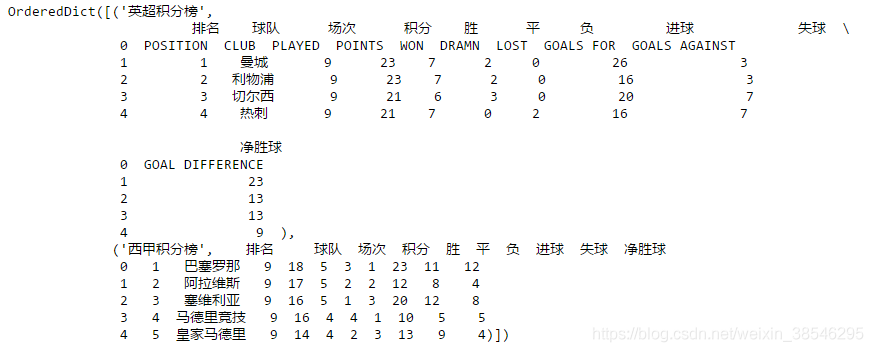
3、header, 用哪一行作列名
- 默认为0 ,如果设置为[0,1],则表示将前两行作为多重索引。
data = pd.read_excel(io, sheet_name = '英超积分榜', header = [0,1])
# 前两行作为列名。
data.head()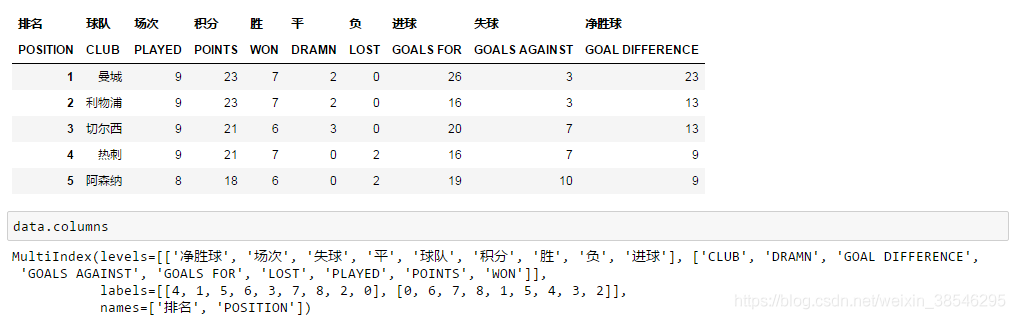
4、names, 自定义最终的列名
- 一般适用于Excel缺少列名,或者需要重新定义列名的情况。
- 注意:names的长度必须和Excel列长度一致,否则会报错。
data = pd.read_excel(io, sheet_name = '英超射手榜',
names = ['rank','player','club','goal','common_goal','penalty'])
data.head()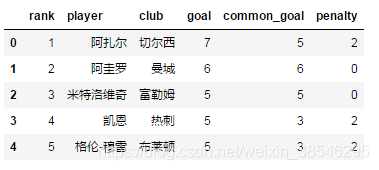
5、index_col, 用作索引的列
- 可以是工作表列名称,如index_col = '排名';
- 可以是整型或整型列表,如index_col = 0 或 [0, 1],如果选择多个列,则返回多重索引。
data = pd.read_excel(io, sheet_name = '英超射手榜', index_col = '排名')
data.head()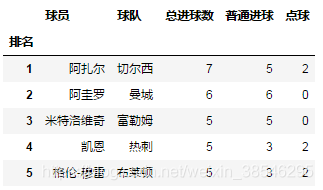
data = pd.read_excel(io, sheet_name = '英超射手榜', index_col = [0, 1])
data.head()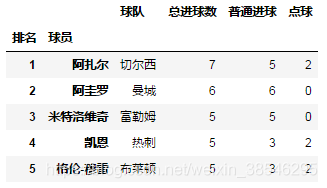
6、usecols,需要读取哪些列
- 可以使用整型,从0开始,如[0,2,3];
- 可以使用Excel传统的列名“A”、“B”等字母,如“A:C, E” ="A, B, C, E",注意两边都包括。
- usecols 可避免读取全量数据,而是以分析需求为导向选择特定数据,可以大幅提高效率。
data = pd.read_excel(io, sheet_name = '西甲射手榜', usecols = [0, 1, 3])
data.head()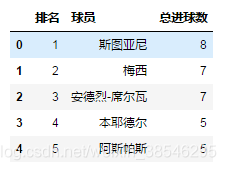
data = pd.read_excel(io, sheet_name = '西甲射手榜', usecols = 'A:C, E')
data.head()
# 啊?什么!!为啥不见C罗??
# 大佬,C罗转会去尤文图斯啦~~~~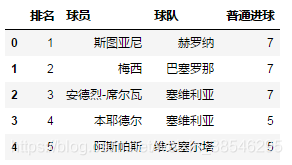
7、squeeze,当数据仅包含一列
- squeeze为True时,返回Series,反之返回DataFrame。
data = pd.read_excel(io, sheet_name = 'squeeze', squeeze = True)
data.head()
data = pd.read_excel(io, sheet_name = 'squeeze', squeeze = False)
data.head()
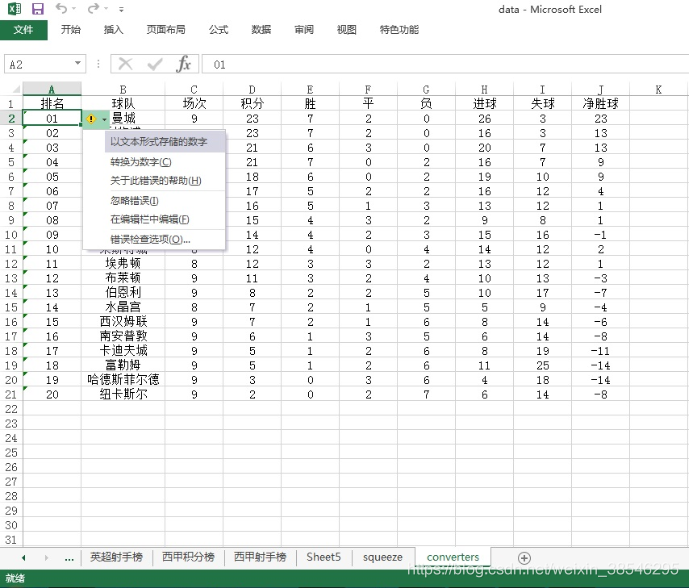
8、converters ,强制规定列数据类型
converters = {'排名': str, '场次': int}, 将“排名”列数据类型强制规定为字符串(pandas默认将文本类的数据读取为整型),“场次”列强制规定为整型;
主要用途:保留以文本形式存储的数字。
data = pd.read_excel(io, sheet_name = 'converters')
data['排名'].dtypedata = pd.read_excel(io, sheet_name = 'converters', converters = {'排名': str, '场次': float})
data['排名'].dtype
9、skiprows,跳过特定行
- skiprows= n, 跳过前n行; skiprows = [a, b, c],跳过第a+1,b+1,c+1行(索引从0开始);
- 使用skiprows 后,有可能首行(即列名)也会被跳过。
data = pd.read_excel(io, sheet_name = '英超射手榜', skiprows = [1,2,3])
# 跳过第2,3,4行数据(索引从0开始,包括列名)
data.head()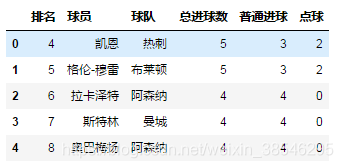
data = pd.read_excel(io, sheet_name = '英超射手榜', skiprows = 3)
data.head()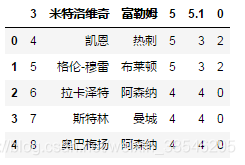
10、nrows ,需要读取的行数
- 如果只想了解Excel的列名及概况,不必读取全量数据,nrows会十分有用。
data = pd.read_excel(io, sheet_name = '英超射手榜', nrows = 10)
data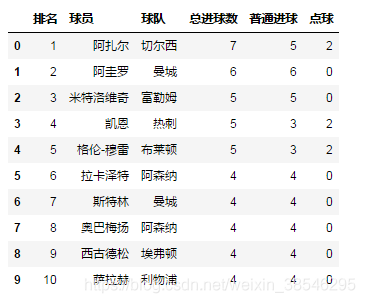
11、skipfooter , 跳过末尾n行
data = pd.read_excel(r'C:\Users\Administrator\Desktop\data.xlsx' ,
sheet_name = '英超射手榜', skipfooter = 43)
# skipfooter = 43, 跳过末尾43行(索引从0开始)
data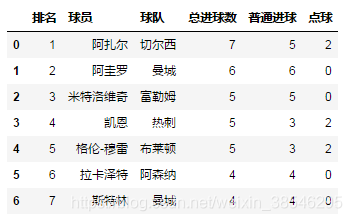
欢迎搜索今日头条“海阔天空爱阅读”,欣赏更多文章~~