文章目录
JVM的内存结构
1、程序计数器(PC Register)
作用:记住下一条jvm指令的执行地址
如下图:我们打的每一条java代码,其实都是在底层执行JVM的指令。每条指令都有其对应的地址,前面说过了,解释器的作用就是逐条执行我们的代码(JVM指令),那么,解释器怎么知道下一条要执行的指令是哪条呢?这就要看程序计数器的了。程序计数器一直保留的都是下一条指令的地址。
上图的流程大概就是:我们自己写java源码,然后java源码被虚拟机翻译成字节码,也就是JVM指令;这些JVM的指令都有各自的地址,他们依次将指令的地址传递给程序计数器,程序计数器就把拿到的地址依次给解释器,解释器寻着地址将我们的字节码(JVM指令)翻译成机器码后交给CPU执行。
特点:
1、线程私有(简单说就是,每个线程都有自己的程序计数器)
2、唯一不会出现内存溢出区域
2、虚拟机栈(JVM Stacks)
2.1、定义
虚拟机栈,是线程运行需要的内存空间。我们java的源码最后其实就是一个个封装起来的方法。每个方法,我们将他们当成一个栈帧(栈帧对应着每次方法调用时所占用的内存)。
每次调用某个方法,我们就把该方法作为一个栈帧(栈中的一个基本单位)放入栈中,如果该方法在执行过程中还调用了其他的方法,那么这些方法也会作为栈帧依次被放入我们的栈中。
如下图:栈帧1、2、3分别对应三个方法。栈帧1调用了栈帧2,栈帧2调用了栈帧3。此时,栈帧3肯定会先运行完,此时栈帧3先运行结束并弹出,然后轮到栈帧2运行结束弹出,最后是栈帧1运行结束后弹出。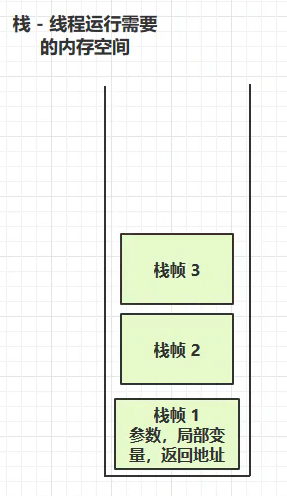
注意:每个线程只能有一个活动栈帧,对应的是当前正在执行的方法。
代码演示:
main方法调用method1()方法,method1()调用method2()方法。
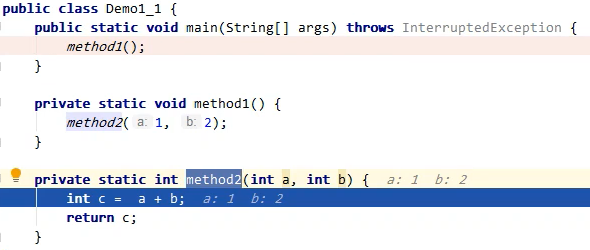
他们的栈如下:(一共有三个栈帧,最下面是main、然后是method1、然后是method2)。其中method2()这个栈帧中放了三个变量(a、b、c)的值

method2()这个栈帧出栈后,我们可以看到,a、b、c 这三个变量已经被回收了。(这里特别说明一下,垃圾回收并不需要管理我们的栈内存,因为当栈帧被弹出的时候,他就会自动释放内存,垃圾回收只需要对堆中无用的对象进行垃圾回收)
我们可以使用-Xss size 来设置我们的栈内存,但是不建议设置而且栈内存越大并不是越好。栈内存大的话,能允许我们进行更多次的方法递归调用,但并不会增加运行的效率;由于内存的局限性,还会导致我们线程数目的变少。
默认情况下:
Linux和MacOS的栈内存是1024KB。
Windows则根据机身的虚拟内存决定。
虚拟机的命令写在下图这里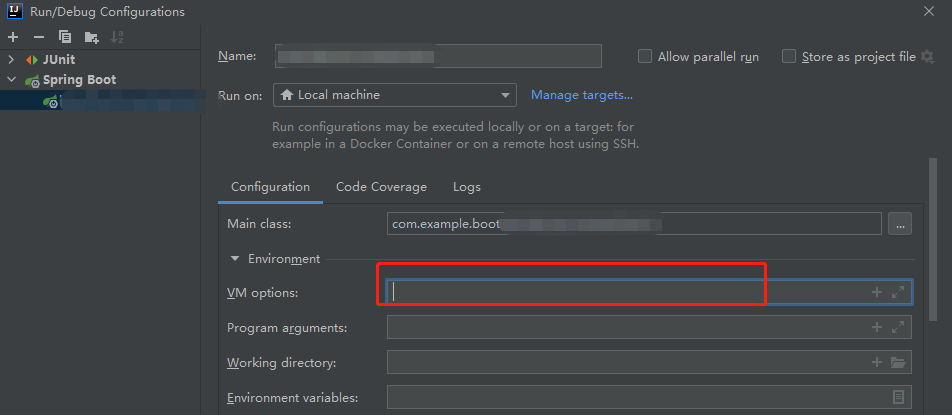
以下三条指令都可以修改我们的栈内存为1024KB。
扩展知识点:
1、方法内的局部变量是否是线程安全的?
这个具体要看该变量是否是线程私有的,如果是线程私有的,那么他是线程安全的,如果他是共有的,那么他就不是线程安全的。
2.2、栈内存溢出
导致栈内存溢出的情况有如下几种:
1、栈帧过多(多次的递归调用)
2、栈帧过大(不太容易出现)
栈帧过多的例子如下:
这里count是类的静态变量。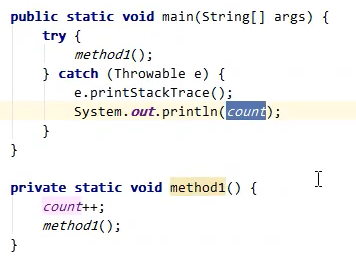
栈内存溢出的报错信息如下:
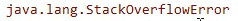
当然了,很多人可能会觉得,我才没那么傻写出上面这种代码呢?那如果,我们是在调用某个库的某个接口导致内存溢出的情况下呢?先看看下方的代码:(这是个一定会裂开的代码,可以自行先找找错)
importcom.fasterxml.jackson.annotation.JsonIgnore;importcom.fasterxml.jackson.core.JsonProcessingException;importcom.fasterxml.jackson.databind.ObjectMapper;importcom.fasterxml.jackson.databind.SerializationFeature;importjava.io.IOException;importjava.util.Arrays;importjava.util.List;publicclassStackOver{publicstaticvoidmain(String[] args)throwsIOException{//创建一个部门对象Dept dept=newDept();
dept.setName("研发部门");//创建两个员工对象Emp emp1=newEmp();
emp1.setName("张三");
emp1.setDept(dept);Emp emp2=newEmp();
emp2.setName("李四");
emp2.setDept(dept);//将员工加入部门对象
dept.setEmpList(Arrays.asList(emp1, emp2));//将部门对象转换为JSON对象ObjectMapper mapper=newObjectMapper();System.out.println(mapper.writeValueAsString(dept));}//部门类staticclassDept{privateString name;//部门名privateList<Emp> empList;//员工列表publicvoidsetName(String name){this.name= name;}publicvoidsetEmpList(List<Emp> empList){this.empList= empList;}publicStringgetName(){return name;}publicList<Emp>getEmpList(){return empList;}}//员工类staticclassEmp{privateString name;//员工名privateDept dept;//所属部门publicvoidsetName(String name){this.name= name;}publicvoidsetDept(Dept dept){this.dept= dept;}publicStringgetName(){return name;}publicDeptgetDept(){return dept;}}}这里,其实有个大bug,在我们将Dept对象转换为JSON对象的时候。他是这样的:
{
name: ‘研发部门’,
empList:[
{
name: ‘张三’,
//问题就出在这里,他的每个员工又包含了部门这个对象,然后部门又包含了员工,员工再包含部门,无穷尽也…
dept: [
name: ‘研发部门’,
empList: [ {name:‘张三’, dept:[…]}, {name:‘李四’, dept[…]} ]
],…
}
]
}
解决方法:(禁止套娃,我们已经知道员工是部门的empList属性中的一员了,那我们就没必要再在员工中输出他是哪个部门的了,使用注解@JsonIgnore将Emp类中的private Dept dept;属性进行忽略即可。)
//员工类staticclassEmp{privateString name;//员工名@JsonIgnoreprivateDept dept;//所属部门publicvoidsetName(String name){this.name= name;}publicvoidsetDept(Dept dept){this.dept= dept;}publicStringgetName(){return name;}publicDeptgetDept(){return dept;}}2.3、线程运行诊断
案例一:CPU占用过多
当某个程序出现CPU占用过多的情况的时候,大部分情况下,可能是我们的线程出现问题了。
我们可以写一个程序大致如下:
publicclassHighCpuUse{publicstaticvoidmain(String[] args){//创建线程1newThread(null,()->{System.out.println("The Thread 1 is running......");while(true){//啥也不干,就这么耗着}},"Thread1").start();//创建线程2newThread(null,()->{System.out.println("The Thread2 is running......");try{Thread.sleep(1000000L);}catch(InterruptedException e){
e.printStackTrace();}},"Thread2").start();//创建线程3newThread(null,()->{System.out.println("The Thread3 is running......");try{Thread.sleep(1000000L);}catch(InterruptedException e){
e.printStackTrace();}},"Thread3").start();}}在Linux系统运行后,使用top命令可以看到:
有个java程序,cpu占用106.7%,而且他的进程id是17656.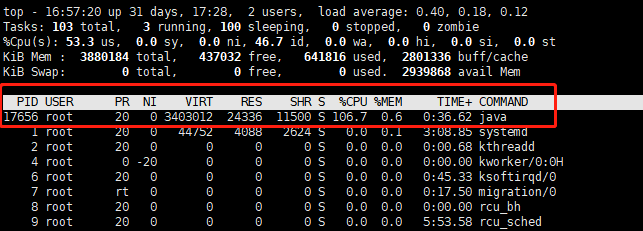
行,我们通过以下命令看一下进行进程号为17656的 进程号,线程号和CPU使用率来看一下:
ps H -eo pid,tid,%cpu | grep 17656
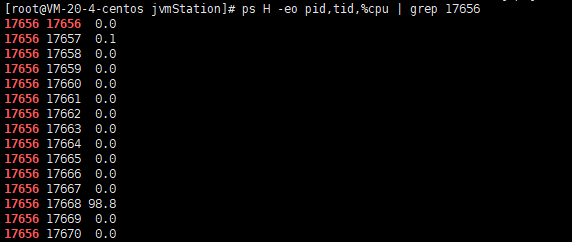
这里,我们可以看到,我们进程号为17656且线程号为17668,他的CPU占用率高达98.8%。然后我们再通过以下命令查看当前进程的所有线程的具体信息。
jstack 进程号
jstack 21345
运行结果如下:
通过17668(CPU占用最多的线程号)这个线程号转化成十六进制,可以得出,17668 = 0x4504(十六进制)。可以定位到导致CPU高占用的就是这个Thread1的进程,而这个进程他在源码中的第5行。
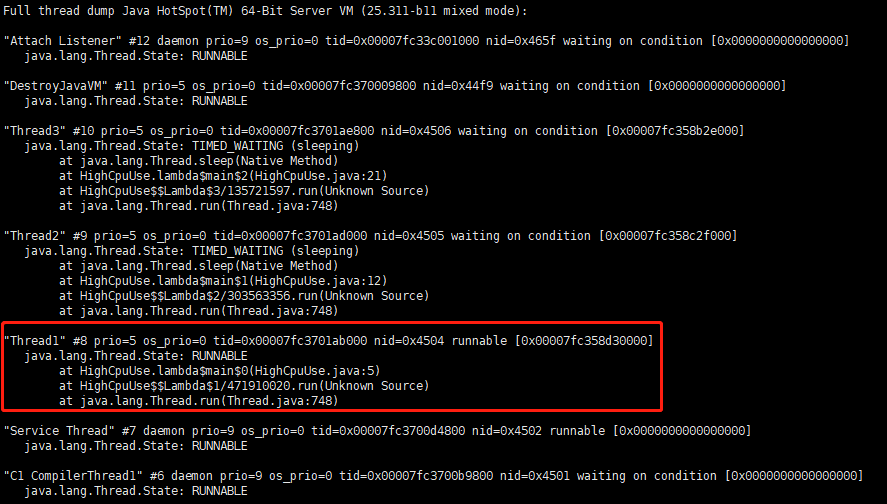
这个时候,我们就可以先把进程杀掉。然后去指定位置修改自己的源码了。杀死进程的命令:
kill -9 17668
案例2:程序运行很长时间没有结果(可能是出现了死锁)
假如我们现在有代码如下:
A.class
publicclassA{}B.class
publicclassB{}ThreadDeadLock.java
publicclassThreadDeadLock{privatestaticA a=newA();privatestaticB b=newB();publicstaticvoidmain(String[] args)throwsInterruptedException{newThread(()->{//线程一开始就锁住a(同步阻塞)synchronized(a){try{//睡两秒Thread.sleep(2000);}catch(InterruptedException e){
e.printStackTrace();}//获取b的资源synchronized(b){System.out.println("我获得了a和b的资源");}}},"Thread1").start();//睡眠1sThread.sleep(1000);newThread(()->{//线程一开始就锁住b(同步阻塞)synchronized(b){synchronized(a){System.out.println("我获得了a和b的资源");}}}).start();}}使用javac编译后,使用以下命令:
nohup java ThreadDeadLock &
可以看到
我们的进程号是22065。
我们来看一下为啥子,这个程序没有输出内容我获得了a和b的资源。
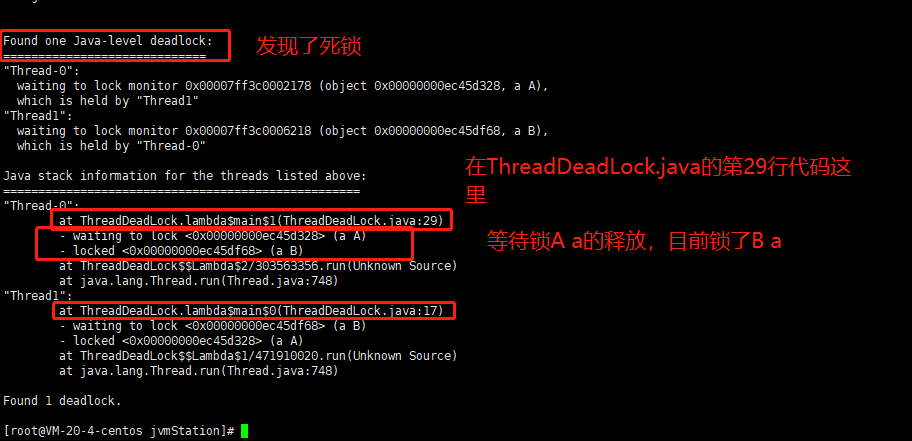 然后,我们就可以针对他所说的死锁,到源码第17和29行进行更改。
然后,我们就可以针对他所说的死锁,到源码第17和29行进行更改。
3、本地方法栈(Native Method Stacks)
本地方法栈的作用是给本地方法提供内存空间。那什么叫本地方法呢?其实就是指那些不是由Java编写的代码,由于我们的Java代码具有一定的限制,有的时候无法直接与操作系统底层打交道,所以就需要一些由C或C++编写的本地方法来真正与操作系统底层的API打交道,我们的Java代码则间接通过本地方法来调用底层的功能。而这些本地方法运行的时候使用的内存,我们将之称之为本地方法栈。
这种本地方法非常多,在我们的基础类库或执行引擎中,他们都会去调用这些本地方法。举个例子:我们所有类的祖先Object。
这些个方法中带有native的,我们可以看到,他们都是没有具体实现的。其实就是本地方法。这个类中还有很多,例如,clone()、notify()、notifyAll()等等。有兴趣的小伙伴可以自己去看看。