目录
通过Keras Model.fit()使用TensorBoard
简介
TensorBoard:TensorFlow的可视化组件
TensorBoard提供了机器学习实验中的可视化和工具
- 跟踪和可视化损失、精确度等矩阵
- 可视化模型图
- 展示权重、偏置或其它张量随时间变化的直方图
- 将embedding映射到低维空间
- 展示图像、文本和音频数据
- 描绘TensorFlow项目
- 等等
上手
在机器学习中,为了提升某项指标,通常需要对其进行评估。TensorBoard可以在机器学习工作流中提供评估标准和可视化。可以跟踪loss、accuracy等实验结果矩阵,可视化模型图,将embedding映射到低维的空间等等。
这篇入门文章将阐述如何快速上手TensorBoard。这个网站中其它部分讲述了TensorFlow具体功能的细节,很多在这篇入门文章中并没有包括。
# 载入TensorBoard notebook扩展
#(我是TensorFlow2.0.0版本,python命令行执行这句会报错,估计要在notebook/jupyter执行,不执行也可以继续用,就没管了,哪位知道这个扩展是干啥的,请留言~)
%load_ext tensorboardimport tensorflow as tf
import datetime
#删除之前运行的日志(默认是在当前目录下新建logs文件夹存放日志,也可指定其它目录)
#如下语句在jupyter运行,也可在命令行直接运行,需去掉!,直接rm -rf ./logs/
!rm -rf ./logs/使用MNIST数据集作为样例,规范化数据并写函数创建简单的Keras模型来将图片分为10类。
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model():
return tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])通过Keras Model.fit()使用TensorBoard
当通过Keras's Model.fit()来训练时,加入kf.keras.callback.TensorBoard回调确保创建并存储日志。另外,通过设置histogram_freq=1(默认关闭)来允许在每个epoch中计算直方图。
把日志放在时间戳子目录,这样可以方便地选择不同的训练过程。
model = create_model()
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
log_dir="logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train,
y=y_train,
epochs=5,
validation_data=(x_test, y_test),
callbacks=[tensorboard_callback])通过命令行或者notebook开启TensorBoard。这两种方式效果一样,在notebook中,使用%tensorboard命令。在命令行中,使用相同的命令,只是不加"%"
%tensorboard --logdir logs/fit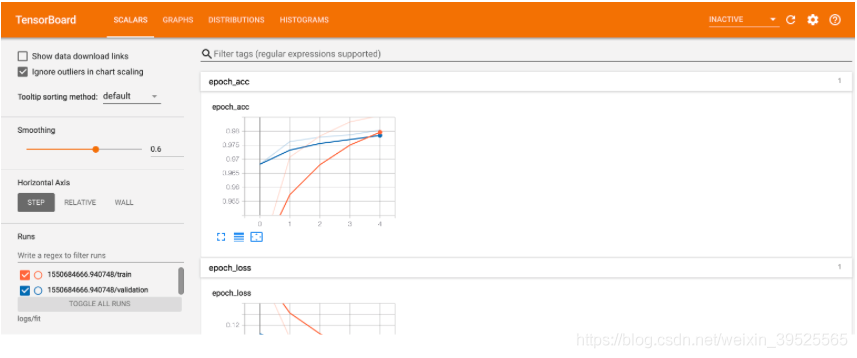
简单介绍下仪表盘(导航栏的选项)
Scalars栏展示了损失和精确度矩阵每个epoch变化情况,可以用来跟踪训练速度,学习率和其它标量值。
Graph栏可以可视化模型,展示模型中的层,帮助用户确定模型建的是否对。
Distributions和Histograms栏展示了张量(可简单理解为数据)随时间变化的分布情况。这个功能可用来可视化权重和偏置,并确定它们在按照用户预期变化。
当记录其它类型的数据时,额外的TensorBoard插件会自动开启。比如,Keras TensorBoard callback允许用户log图像和embedding。
通过其它方法使用TensorBoard
当通过tf.GradientTape()等方法训练时,使用tf.summary来记录所需信息。
同样使用MNIST 数据集,转换为tf.data.Dataset来利用批处理能力
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
train_dataset = train_dataset.shuffle(60000).batch(64)
test_dataset = test_dataset.batch(64)训练的代码和高级快速入门教程一致,但是加入了将矩阵保存到TensorBoard的部分。选择损失函数和优化器:
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()创建状态指标来保留训练时的数据并随时记录
# Define our metrics
train_loss = tf.keras.metrics.Mean('train_loss', dtype=tf.float32)
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('train_accuracy')
test_loss = tf.keras.metrics.Mean('test_loss', dtype=tf.float32)
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy('test_accuracy')定义训练和测试函数
def train_step(model, optimizer, x_train, y_train):
with tf.GradientTape() as tape:
predictions = model(x_train, training=True)
loss = loss_object(y_train, predictions)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
train_loss(loss)
train_accuracy(y_train, predictions)
def test_step(model, x_test, y_test):
predictions = model(x_test)
loss = loss_object(y_test, predictions)
test_loss(loss)
test_accuracy(y_test, predictions)创建summary writer来将日志写入磁盘的不同目录
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'
train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)开始训练。使用tf.summary.scalar() 来在训练和测试过程记录指标(loss 和 精确度)并写入磁盘。用户可指定记录哪些指标以及记录的频率。其它tf.summary函数允许记录其它类型的数据。
model = create_model() # reset our model
EPOCHS = 5
for epoch in range(EPOCHS):
for (x_train, y_train) in train_dataset:
train_step(model, optimizer, x_train, y_train)
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (x_test, y_test) in test_dataset:
test_step(model, x_test, y_test)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print (template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
# Reset metrics every epoch
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()训练过程结束后,打开TensorBoard,这次给它指定新的目录。(训练过程中也可以开启TensorBoard来监控训练。)
%tensorboard --logdir logs/gradient_tape现在你知道如何通过Keras回调和tf.summary来使用TensorBoard了。tf.summary可支持更多自定义方案。