通常我们习惯将编码(Encode)称为序列化(serialization),它将对象序列化为字节数组,用于网络传输、数据持久化或者其它用途。
反之,解码(Decode)称为反序列化(deserialization),它把从网络、磁盘等读取的字节数组还原成原始对象(通常是原始对象的拷贝),以方便后续的业务逻辑操作。
Java序列化
相信大多数Java程序员接触到的第一种序列化或者编解码技术就是Java默认提供的序列化机制,需要序列化的Java对象只需要实现java.io.Serializable接口并生成序列化ID,这个类就能够通过java.io.ObjectInput和java.io.ObjectOutput序列化和反序列化。可以直接把Java对象作为可存储的字节数组写入文件,也可以传输到网络上,对程序员来说,基于JDK默认的序列化机制可以避免操作底层的字节数组,从而提升开发效率。
Java序列化的目的主要有两个:1.网络传输。2.对象持久化。
Java序列化的缺点:1.无法跨语言。 2.序列化后码流太大。3.序列化性能太低。
Java序列化仅仅是Java编解码技术的一种,由于它的种种缺陷,衍生出了多种编解码技术和框架,这些编解码框架实现消息的高效序列化。
其他序列化框架
Java默认的序列化机制效率很低、序列化后的码流也较大,所以涌现出了非常多的优秀的Java序列化框架,例如:hessian、protobuf、thrift、protostuff、kryo、msgpack、avro、fst 等等。
Netty自带的编解码器
Netty提供了编解码器框架,使得编写自定义的编解码器很容易,并且也很容易重用和封装。Netty提供了 io.netty.handler.codec.MessageToByteEncoder和io.netty.handler.codec.ByteToMessageDecoder接口,方便我们扩展编解码。
Codec,编解码器
Decoder,解码器
Encoder,编码器
编解码器Codec
因为编解码器由两部分组成:Decoder(解码器),Encoder(编码器)编码器。负责将消息从字节或其他序列形式转成指定的消息对象,编码器则相反;解码器负责处理“入站”数据,编码器负责处理“出站”数据。编码器和解码器的结构很简单,消息被编码后解码后会自动通过ReferenceCountUtil.release(message)释放,如果不想释放消息可以使用ReferenceCountUtil.retain(message),这将会使引用数量增加而没有消息发布,大多数时候不需要这么做。
解码器
Netty提供了丰富的解码器抽象基类,我们可以很容易的实现这些基类来自定义解码器。下面是解码器的一个类型:
解码字节到消息(ByteToMessageDecoder,ReplayingDecoder)
解码消息到消息(MessageToMessageDecoder)
解码器负责解码“入站”数据从一种格式到另一种格式,解码器处理入站数据是抽象ChannelInboundHandler的实现。实践中使用解码器很简单,就是将入站数据转换格式后传递到ChannelPipeline中的下一个ChannelInboundHandler进行处理;这样的处理时很灵活的,我们可以将解码器放在ChannelPipeline中,重用逻辑。
ByteToMessageDecoder
通常你需要将消息从字节解码成消息或者从字节解码成其他的序列化字节。这是一个常见的任务,Netty提供了抽象基类,我们可以使用它们来实现。Netty中提供的ByteToMessageDecoder可以将字节消息解码成POJO对象,下面列出了ByteToMessageDecoder两个主要方法:
decode(ChannelHandlerContext, ByteBuf, List<Object>),这个方法是唯一的一个需要自己实现的抽象方法,作用是将ByteBuf数据解码成其他形式的数据。
decodeLast(ChannelHandlerContext, ByteBuf, List<Object>),实际上调用的是decode(...)。
例如服务器从某个客户端接收到一个整数值的字节码,服务器将数据读入ByteBuf并经过ChannelPipeline中的每个ChannelInboundHandler进行处理,看下图:
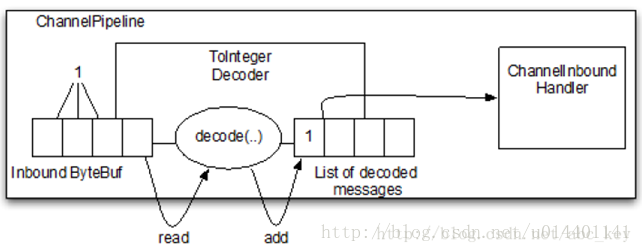
上图显示了从“入站”ByteBuf读取bytes后由ToIntegerDecoder进行解码,然后向解码后的消息传递到ChannelPipeline中的下一个ChannelInboundHandler。看下面ToIntegerDecoder的实现代码:
/**
* Integer解码器,ByteToMessageDecoder实现
* @author c.k
*
*/
public class ToIntegerDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
if(in.readableBytes() >= 4){
out.add(in.readInt());
}
}
}从上面的代码可能会发现,我们需要检查ByteBuf读之前是否有足够的字节,若没有这个检查岂不更好?是的,Netty提供了这样的处理允许byte-to-message解码。除了ByteToMessageDecoder之外,Netty还提供了许多其他的解码接口。
ReplayingDecoder
ReplayingDecoder是byte-to-message解码的一种特殊的抽象基类,读取缓冲区的数据之前需要检查缓冲区是否有足够的字节,使用ReplayingDecoder就无需自己检查;若ByteBuf中有足够的字节,则会正常读取;若没有足够的字节则会停止解码。也正因为这样的包装使得ReplayingDecoder带有一定的局限性。
不是所有的操作都被ByteBuf支持,如果调用一个不支持的操作会抛出DecoderException。
ByteBuf.readableBytes()大部分时间不会返回期望值
如果你能忍受上面列出的限制,相比ByteToMessageDecoder,你可能更喜欢ReplayingDecoder。在满足需求的情况下推荐使用ByteToMessageDecoder,因为它的处理比较简单,没有ReplayingDecoder实现的那么复杂。ReplayingDecoder继承与ByteToMessageDecoder,所以他们提供的接口是相同的。下面代码是ReplayingDecoder的实现:
/**
* Integer解码器,ReplayingDecoder实现
* @author c.k
*
*/
public class ToIntegerReplayingDecoder extends ReplayingDecoder<Void> {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
out.add(in.readInt());
}
}当从接收的数据ByteBuf读取integer,若没有足够的字节可读,decode(...)会停止解码,若有足够的字节可读,则会读取数据添加到List列表中。使用ReplayingDecoder或ByteToMessageDecoder是个人喜好的问题,Netty提供了这两种实现,选择哪一个都可以。
MessageToMessageDecoder
将消息对象转成消息对象可是使用MessageToMessageDecoder,它是一个抽象类,需要我们自己实现其decode(...)。message-to-message同上面讲的byte-to-message的处理机制一样,看下图:
看下面的实现代码:
/**
* 将接收的Integer消息转成String类型,MessageToMessageDecoder实现
* @author c.k
*
*/
public class IntegerToStringDecoder extends MessageToMessageDecoder<Integer> {
@Override
protected void decode(ChannelHandlerContext ctx, Integer msg, List<Object> out) throws Exception {
out.add(String.valueOf(msg));
}
}编码器
Netty提供了一些基类,我们可以很简单的编码器。同样的,编码器有下面两种类型:
消息对象编码成消息对象(MessageToMessageEncoder)
消息对象编码成字节码(MessageToByteEncoder)
相对解码器,编码器少了一个byte-to-byte的类型,因为出站数据这样做没有意义。编码器的作用就是将处理好的数据转成字节码以便在网络中传输。对照上面列出的两种编码器类型,Netty也分别提供了两个抽象类:MessageToByteEncoder和MessageToMessageEncoder。下面是类关系图:
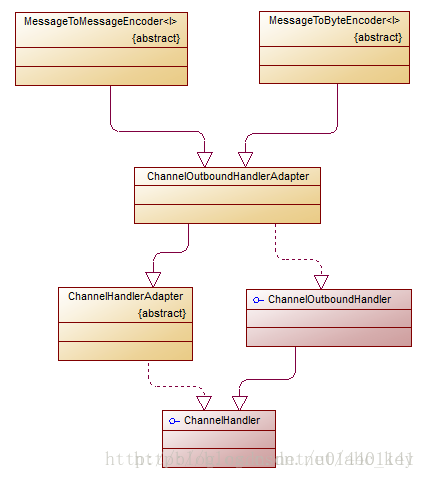
MessageToByteEncoder
MessageToByteEncoder是抽象类,我们自定义一个继承MessageToByteEncoder的编码器只需要实现其提供的encode(...)方法。其工作流程如下图:
实现代码如下:
/**
* 编码器,将Integer值编码成byte[],MessageToByteEncoder实现
* @author c.k
*
*/
public class IntegerToByteEncoder extends MessageToByteEncoder<Integer> {
@Override
protected void encode(ChannelHandlerContext ctx, Integer msg, ByteBuf out) throws Exception {
out.writeInt(msg);
}
}MessageToMessageEncoder
需要将消息编码成其他的消息时可以使用Netty提供的MessageToMessageEncoder抽象类来实现。例如将Integer编码成String,其工作流程如下图:
代码实现如下:
/**
* 编码器,将Integer编码成String,MessageToMessageEncoder实现
*
*/
public class IntegerToStringEncoder extends MessageToMessageEncoder<Integer> {
@Override
protected void encode(ChannelHandlerContext ctx, Integer msg, List<Object> out) throws Exception {
out.add(String.valueOf(msg));
}
}编解码器
实际编码中,一般会将编码和解码操作封装太一个类中,解码处理“入站”数据,编码处理“出站”数据。知道了编码和解码器,对于下面的情况不会感觉惊讶:
(byte-to-message)编码和解码
(message-to-message)编码和解码
如果确定需要在ChannelPipeline中使用编码器和解码器,需要更好的使用一个抽象的编解码器。同样,使用编解码器的时候,不可能只删除解码器或编码器而离开ChannelPipeline导致某种不一致的状态。使用编解码器将强制性的要么都在ChannelPipeline,要么都不在ChannelPipeline。
考虑到这一点,我们在下面几节将更深入的分析Netty提供的编解码抽象类。
byte-to-byte编解码器
Netty4较之前的版本,其结构有很大的变化,在Netty4中实现byte-to-byte提供了2个类:ByteArrayEncoder和ByteArrayDecoder。这两个类用来处理字节到字节的编码和解码。下面是这两个类的源码,一看就知道是如何处理的:
public class ByteArrayDecoder extends MessageToMessageDecoder<ByteBuf> {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception {
// copy the ByteBuf content to a byte array
byte[] array = new byte[msg.readableBytes()];
msg.getBytes(0, array);
out.add(array);
}
}
@Sharable
public class ByteArrayEncoder extends MessageToMessageEncoder<byte[]> {
@Override
protected void encode(ChannelHandlerContext ctx, byte[] msg, List<Object> out) throws Exception {
out.add(Unpooled.wrappedBuffer(msg));
}
}ByteToMessageCodec
ByteToMessageCodec用来处理byte-to-message和message-to-byte。如果想要解码字节消息成POJO或编码POJO消息成字节,对于这种情况,ByteToMessageCodec<I>是一个不错的选择。ByteToMessageCodec是一种组合,其等同于ByteToMessageDecoder和MessageToByteEncoder的组合。MessageToByteEncoder是个抽象类,其中有2个方法需要我们自己实现:
encode(ChannelHandlerContext, I, ByteBuf),编码
decode(ChannelHandlerContext, ByteBuf, List<Object>),解码
MessageToMessageCodec
MessageToMessageCodec用于message-to-message的编码和解码,可以看成是MessageToMessageDecoder和MessageToMessageEncoder的组合体。MessageToMessageCodec是抽象类,其中有2个方法需要我们自己实现:
encode(ChannelHandlerContext, OUTBOUND_IN, List<Object>)
decode(ChannelHandlerContext, INBOUND_IN, List<Object>)
但是,这种编解码器能有用吗?
有许多用例,最常见的就是需要将消息从一个API转到另一个API。这种情况下需要自定义API或旧的API使用另一种消息类型。下面的代码显示了在WebSocket框架APIs之间转换消息:
package netty.in.action;
import java.util.List;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelHandler.Sharable;
import io.netty.handler.codec.MessageToMessageCodec;
import io.netty.handler.codec.http.websocketx.BinaryWebSocketFrame;
import io.netty.handler.codec.http.websocketx.CloseWebSocketFrame;
import io.netty.handler.codec.http.websocketx.ContinuationWebSocketFrame;
import io.netty.handler.codec.http.websocketx.PingWebSocketFrame;
import io.netty.handler.codec.http.websocketx.PongWebSocketFrame;
import io.netty.handler.codec.http.websocketx.TextWebSocketFrame;
import io.netty.handler.codec.http.websocketx.WebSocketFrame;
@Sharable
public class WebSocketConvertHandler extends
MessageToMessageCodec<WebSocketFrame, WebSocketConvertHandler.MyWebSocketFrame> {
public static final WebSocketConvertHandler INSTANCE = new WebSocketConvertHandler();
@Override
protected void encode(ChannelHandlerContext ctx, MyWebSocketFrame msg, List<Object> out) throws Exception {
switch (msg.getType()) {
case BINARY:
out.add(new BinaryWebSocketFrame(msg.getData()));
break;
case CLOSE:
out.add(new CloseWebSocketFrame(true, 0, msg.getData()));
break;
case PING:
out.add(new PingWebSocketFrame(msg.getData()));
break;
case PONG:
out.add(new PongWebSocketFrame(msg.getData()));
break;
case TEXT:
out.add(new TextWebSocketFrame(msg.getData()));
break;
case CONTINUATION:
out.add(new ContinuationWebSocketFrame(msg.getData()));
break;
default:
throw new IllegalStateException("Unsupported websocket msg " + msg);
}
}
@Override
protected void decode(ChannelHandlerContext ctx, WebSocketFrame msg, List<Object> out) throws Exception {
if (msg instanceof BinaryWebSocketFrame) {
out.add(new MyWebSocketFrame(MyWebSocketFrame.FrameType.BINARY, msg.content().copy()));
return;
}
if (msg instanceof CloseWebSocketFrame) {
out.add(new MyWebSocketFrame(MyWebSocketFrame.FrameType.CLOSE, msg.content().copy()));
return;
}
if (msg instanceof PingWebSocketFrame) {
out.add(new MyWebSocketFrame(MyWebSocketFrame.FrameType.PING, msg.content().copy()));
return;
}
if (msg instanceof PongWebSocketFrame) {
out.add(new MyWebSocketFrame(MyWebSocketFrame.FrameType.PONG, msg.content().copy()));
return;
}
if (msg instanceof TextWebSocketFrame) {
out.add(new MyWebSocketFrame(MyWebSocketFrame.FrameType.TEXT, msg.content().copy()));
return;
}
if (msg instanceof ContinuationWebSocketFrame) {
out.add(new MyWebSocketFrame(MyWebSocketFrame.FrameType.CONTINUATION, msg.content().copy()));
return;
}
throw new IllegalStateException("Unsupported websocket msg " + msg);
}
public static final class MyWebSocketFrame {
public enum FrameType {
BINARY, CLOSE, PING, PONG, TEXT, CONTINUATION
}
private final FrameType type;
private final ByteBuf data;
public MyWebSocketFrame(FrameType type, ByteBuf data) {
this.type = type;
this.data = data;
}
public FrameType getType() {
return type;
}
public ByteBuf getData() {
return data;
}
}
}其他编解码方式
使用编解码器来充当编码器和解码器的组合失去了单独使用编码器或解码器的灵活性,编解码器是要么都有要么都没有。你可能想知道是否有解决这个僵化问题的方式,还可以让编码器和解码器在ChannelPipeline中作为一个逻辑单元。幸运的是,Netty提供了一种解决方案,使用CombinedChannelDuplexHandler。虽然这个类不是编解码器API的一部分,但是它经常被用来简历一个编解码器。
CombinedChannelDuplexHandler
如何使用CombinedChannelDuplexHandler来结合解码器和编码器呢?下面我们从两个简单的例子看了解。
/**
* 解码器,将byte转成char
* @author c.k
*
*/
public class ByteToCharDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
while(in.readableBytes() >= 2){
out.add(Character.valueOf(in.readChar()));
}
}
}/**
* 编码器,将char转成byte
* @author Administrator
*
*/
public class CharToByteEncoder extends MessageToByteEncoder<Character> {
@Override
protected void encode(ChannelHandlerContext ctx, Character msg, ByteBuf out) throws Exception {
out.writeChar(msg);
}
}/**
* 继承CombinedChannelDuplexHandler,用于绑定解码器和编码器
* @author c.k
*
*/
public class CharCodec extends CombinedChannelDuplexHandler<ByteToCharDecoder, CharToByteEncoder> {
public CharCodec(){
super(new ByteToCharDecoder(), new CharToByteEncoder());
}
}从上面代码可以看出,使用CombinedChannelDuplexHandler绑定解码器和编码器很容易实现,比使用*Codec更灵活。
Java有许多序列化框架,例如:hessian、protobuf、thrift、protostuff、kryo、msgpack、avro、fst 等。
Netty本身集成一些,提供这些的协议支持,放在io.netty.handler.codec包下,如:
Google的protobuf,在io.netty.handler.codec.protobuf包下
Google的SPDY协议
RTSP(Real Time Streaming Protocol,实时流传输协议),在io.netty.handler.codec.rtsp包下
SCTP(Stream Control Transmission Protocol,流控制传输协议),在io.netty.handler.codec.sctp包下
通过集成其他序列化框架来编解码
Google的Protobuf
Protobuf全称Google Protocol Buffers,它由谷歌开源而来,在谷歌内部久经考验。它将数据结构以.proto文件进行描述,通过代码生成工具可以生成对应数据结构的POJO对象和Protobuf相关的方法和属性。
它的特点如下:
1) 结构化数据存储格式(XML,JSON等);
2) 高效的编解码性能;
3) 语言无关、平台无关、扩展性好;
4) 官方支持Java、C++和Python三种语言。
首先我们来看下为什么不使用XML,尽管XML的可读性和可扩展性非常好,也非常适合描述数据结构,但是XML解析的时间开销和XML为了可读性而牺牲的空间开销都非常大,因此不适合做高性能的通信协议。Protobuf使用二进制编码,在空间和性能上具有更大的优势。
Protobuf另一个比较吸引人的地方就是它的数据描述文件和代码生成机制,利用数据描述文件对数据结构进行说明的优点如下:
1) 文本化的数据结构描述语言,可以实现语言和平台无关,特别适合异构系统间的集成;
2) 通过标识字段的顺序,可以实现协议的前向兼容;
3) 自动代码生成,不需要手工编写同样数据结构的C++和Java版本;
4) 方便后续的管理和维护。相比于代码,结构化的文档更容易管理和维护。
Protostuff
官网:https://code.google.com/p/protostuff/。
Protostuff是基于大名鼎鼎的Google protobuff技术的Java版,它较于protobuf最明显的好处是,在几乎不损耗性能的情况下做到了不用我们写.proto文件来实现序列化。Protostuff反序列化时并不要求类型匹配,比如包名、类名甚至是字段名,它仅仅需要序列化类型A 和反序列化类型B 的字段类型可转换(比如int可以转换为long)即可。
Apache的Thrift
Thrift源于Facebook,Thrift可以支持多种程序语言,如C++、C#、Cocoa、Erlang、Haskell、Java、Ocami、Perl、PHP、Python、Ruby和Smalltalk。在多种不同的语言之间通信,Thrift可以作为高性能的通信中间件使用,它支持数据(对象)序列化和多种类型的RPC服务。Thrift适用于静态的数据交换,需要先确定好它的数据结构,当数据结构发生变化时,必须重新编辑IDL文件,生成代码和编译,这一点跟其他IDL工具相比可以视为是Thrift的弱项。Thrift适用于搭建大型数据交换及存储的通用工具,对于大型系统中的内部数据传输,相对于JSON和XML在性能和传输大小上都有明显的优势。
Thrift主要由5部分组成:
1) 语言系统以及IDL编译器:负责由用户给定的IDL文件生成相应语言的接口代码;
2) TProtocol:RPC的协议层,可以选择多种不同的对象序列化方式,如JSON和Binary;
3) TTransport:RPC的传输层,同样可以选择不同的传输层实现,如socket、NIO、MemoryBuffer等;
4) TProcessor:作为协议层和用户提供的服务实现之间的纽带,负责调用服务实现的接口;
5) TServer:聚合TProtocol、TTransport和TProcessor等对象。
我们重点关注的是编解码框架,与之对应的就是TProtocol。由于Thrift的RPC服务调用和编解码框架绑定在一起,所以,通常我们使用Thrift的时候会采取RPC框架的方式。但是,它的TProtocol编解码框架还是可以以类库的方式独立使用的。
与Protobuf比较类似的是,Thrift通过IDL描述接口和数据结构定义,它支持8种Java基本类型、Map、Set和List,支持可选和必选定义,功能非常强大。因为可以定义数据结构中字段的顺序,所以它也可以支持协议的前向兼容。
Thrift支持三种比较典型的编解码方式:
1) 通用的二进制编解码;
2) 压缩二进制编解码;
3) 优化的可选字段压缩编解码。
由于支持二进制压缩编解码,Thrift的编解码性能表现也相当优异,远远超过Java序列化和RMI等。
JBoss Marshalling
JBoss Marshalling是一个Java对象的序列化API包,修正了JDK自带的序列化包的很多问题,但又保持跟java.io.Serializable接口的兼容;同时增加了一些可调的参数和附加的特性,并且这些参数和特性可通过工厂类进行配置。
相比于传统的Java序列化机制,它的优点如下:
1) 可插拔的类解析器,提供更加便捷的类加载定制策略,通过一个接口即可实现定制;
2) 可插拔的对象替换技术,不需要通过继承的方式;
3) 可插拔的预定义类缓存表,可以减小序列化的字节数组长度,提升常用类型的对象序列化性能;
4) 无须实现java.io.Serializable接口,即可实现Java序列化;
5) 通过缓存技术提升对象的序列化性能。
相比于前面介绍的两种编解码框架,JBoss Marshalling更多是在JBoss内部使用,应用范围有限。
使用Protostuff来序列化示例
1.定义编解码工具接口
/**
* 编解码接口
*/
public interface Serializer {
byte[] encode(Object msg) throws IOException;
<T> T decode(byte[] buf, Class<T> type) throws IOException;
}
2.使用Protostuff来实现编解码工具接口
public class ProtostuffSerializer implements Serializer {
//构建schema的过程可能会比较耗时,因此希望使用过的类对应的schema能被缓存起来
private static final LoadingCache<Class<?>, Schema<?>> schemas = CacheBuilder.newBuilder()
.build(new CacheLoader<Class<?>, Schema<?>>() {
@Override
public Schema<?> load(Class<?> cls) throws Exception {
return RuntimeSchema.createFrom(cls);
}
});
@Override
public byte[] encode(Object msg) throws IOException {
LinkedBuffer buffer = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
try {
Schema schema = getSchema(msg.getClass());
byte[] arr = ProtostuffIOUtil.toByteArray(msg, schema, buffer);
return arr;
} finally {
buffer.clear();
}
}
@Override
public <T> T decode(byte[] buf, Class<T> type) throws IOException {
Schema<T> schema = getSchema(type);
T msg = schema.newMessage();
ProtostuffIOUtil.mergeFrom(buf, msg, schema);
return (T) msg;
}
private static Schema getSchema(Class<?> cls) throws IOException {
try {
return schemas.get(cls);
} catch (ExecutionException e) {
throw new IOException("create protostuff schema error", e);
}
}
}3.定义Serializer工厂
/**
* 编解码工具类工厂类
*/
public class SerializerFactory {
public static <T> Serializer getSerializer(Class<T> t){
Serializer serializer=null;
try {
serializer= (Serializer) t.newInstance();
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return serializer;
}
}
4.netty编码解码实现类
/**
* netty解码实现类
* @param <T>
* @param <K>
*/
public class NettyMessageDecoder<T, K extends Serializer> extends LengthFieldBasedFrameDecoder {
private Logger logger = LoggerFactory.getLogger(getClass());
//判断传送客户端传送过来的数据是否按照协议传输,头部信息的大小应该是 byte+byte+int = 1+1+4 = 6
private static final int HEADER_SIZE = 6;
private Serializer serializer;
private Class<T> clazz;
public NettyMessageDecoder(Class<T> clazz, Class<K> serial, int maxFrameLength, int lengthFieldOffset,
int lengthFieldLength) throws IOException {
super(maxFrameLength, lengthFieldOffset, lengthFieldLength);
this.clazz = clazz;
this.serializer = SerializerFactory.getSerializer(serial);
}
@Override
protected Object decode(ChannelHandlerContext ctx, ByteBuf in)
throws Exception {
if (in.readableBytes() < HEADER_SIZE) {
return null;
}
in.markReaderIndex();
//注意在读的过程中,readIndex的指针也在移动
byte type = in.readByte();
byte flag = in.readByte();
int dataLength = in.readInt();
if (in.readableBytes() < dataLength) {
logger.error("body length < {}", dataLength);
in.resetReaderIndex();
return null;
}
byte[] data = new byte[dataLength];
in.readBytes(data);
try {
return serializer.decode(data, clazz);
} catch (Exception e) {
throw new RuntimeException("serializer decode error");
}
}
}/**
* netty编码实现类
*
* @param <T>
* @param <K>
*/
public final class NettyMessageEncoder<T, K extends Serializer> extends
MessageToByteEncoder {
private final byte type = 0X00;
private final byte flag = 0X0F;
private Serializer serializer;
private Class<T> clazz;
public NettyMessageEncoder(Class<T> clazz, Class<K> serial) {
this.clazz = clazz;
serializer = SerializerFactory.getSerializer(serial);
}
@Override
protected void encode(ChannelHandlerContext ctx, Object msg,
ByteBuf out) throws Exception {
try {
out.writeByte(type);
out.writeByte(flag);
byte[] data = serializer.encode(msg);
out.writeInt(data.length);
out.writeBytes(data);
} catch (Exception e) {
e.printStackTrace();
}
}
}
5.Handler
客户端
public class ClientHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
try {
ByteBuf buf = (ByteBuf) msg;
byte[] req = new byte[buf.readableBytes()];
buf.readBytes(req);
String body = new String(req, "utf-8");
System.out.println("NettyClient :" + body );
String response = "收到服务器端的返回信息:" + body;
} finally {
ReferenceCountUtil.release(msg);
}
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
throws Exception {
ctx.close();
}
}服务端
public class ServerHandler extends ChannelInboundHandlerAdapter {
//channelActive():客户端连接服务器后被调用
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
System.out.println("server channel active... ");
}
//从服务器接收到数据后调用
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg)
throws Exception {
try {
ByteBuf buf = (ByteBuf) msg;
byte[] req = new byte[buf.readableBytes()];
buf.readBytes(req);
String body = new String(req, "utf-8");
System.out.println("Server :" + body );
String response = "进行返回给客户端的响应:" + body ;
ctx.writeAndFlush(Unpooled.copiedBuffer(response.getBytes()));
} finally {
ReferenceCountUtil.release(msg);
}
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx)
throws Exception {
System.out.println("读完了");
ctx.flush();
}
// 发生异常时被调用
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable t)
throws Exception {
ctx.close();
}
}
6.客户端,服务端
public class Server {
public static void main(String[] args) throws Exception{
EventLoopGroup pGroup = new NioEventLoopGroup();
EventLoopGroup cGroup = new NioEventLoopGroup();
ServerBootstrap b = new ServerBootstrap();
b.group(pGroup, cGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 1024)
//设置日志
.handler(new LoggingHandler(LogLevel.INFO))
.childHandler(new ChannelInitializer<SocketChannel>() {
protected void initChannel(SocketChannel sc) throws Exception {
sc.pipeline().addLast(new NettyMessageDecoder<Request,ProtostuffSerializer>(Request.class,ProtostuffSerializer.class,1<<20, 2, 4));
sc.pipeline().addLast(new NettyMessageEncoder<Response,ProtostuffSerializer>(Response.class,ProtostuffSerializer.class));
sc.pipeline().addLast(new ServerHandler());
}
});
ChannelFuture cf = b.bind(8765).sync();
cf.channel().closeFuture().sync();
pGroup.shutdownGracefully();
cGroup.shutdownGracefully();
}
}public class Client {
public static void main(String[] args) throws Exception{
EventLoopGroup group = new NioEventLoopGroup();
Bootstrap b = new Bootstrap();
b.group(group)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel sc) throws Exception {
sc.pipeline().addLast(new NettyMessageDecoder<Response,ProtostuffSerializer>(Response.class,ProtostuffSerializer.class,1<<20, 2, 4));
sc.pipeline().addLast(new NettyMessageEncoder<Request,ProtostuffSerializer>(Request.class,ProtostuffSerializer.class));
sc.pipeline().addLast(new ClientHandler());
}
});
ChannelFuture cf = b.connect("127.0.0.1", 8765).sync();
for(int i = 0; i < 5; i++ ){
Request req = new Request();
req.setId("" + i);
req.setName("pro" + i);
req.setRequestMessage("数据信息" + i);
String path = "D:\\workFile\\netty-demo\\doc\\" + "0.jpg";
File file = new File(path);
FileInputStream in = new FileInputStream(file);
byte[] data = new byte[in.available()];
in.read(data);
in.close();
req.setAttachment(GzipUtils.gzip(data));
cf.channel().writeAndFlush(req);
}
cf.channel().closeFuture().sync();
group.shutdownGracefully();
}
}
7.请求,响应实体
public class Request {
private String id ;
private String name ;
private String requestMessage ;
private byte[] attachment;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getRequestMessage() {
return requestMessage;
}
public void setRequestMessage(String requestMessage) {
this.requestMessage = requestMessage;
}
public byte[] getAttachment() {
return attachment;
}
public void setAttachment(byte[] attachment) {
this.attachment = attachment;
}
}public class Response{
private String id;
private String name;
private String responseMessage;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getResponseMessage() {
return responseMessage;
}
public void setResponseMessage(String responseMessage) {
this.responseMessage = responseMessage;
}
}主要用到的jar
<!-- protostuff -->
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>${protostuff.version}</version>
</dependency>
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>${protostuff.version}</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>参考: