
- 深度学习基础知识
- numpy实现神经网络构建和梯度下降算法
- 计算机视觉领域主要方向的原理、实践
- 自然语言处理领域主要方向的原理、实践
- 个性化推荐算法的原理、实践
- 使学习快速进行(能够使用较大的学习率)
- 降低模型对初始值的敏感性
- 从一定程度上抑制过拟合
- 读者可以自行验证由构成的mini-batch,是否满足均值为0,方差为1的分布。
- 示例一: 当输入数据形状是时,一般对应全连接层的输出,示例代码如下所示。
- 输入 x, [N, K]
- 输出 y, [N, K]
- 均值 ,[K, ]
- 方差 , [K, ]
- 缩放参数, [K, ]
- 平移参数, [K, ]
# 输入数据形状是 [N, K]时的示例import numpy as npimport paddleimport paddle.fluid as fluidfrom paddle.fluid.dygraph.nn import BatchNorm# 创建数据data = np.array([[1,2,3], [4,5,6], [7,8,9]]).astype('float32')# 使用BatchNorm计算归一化的输出with fluid.dygraph.guard(): # 输入数据维度[N, K],num_channels等于K bn = BatchNorm('bn', num_channels=3) x = fluid.dygraph.to_variable(data) y = bn(x) print('output of BatchNorm Layer: \n {}'.format(y.numpy()))# 使用Numpy计算均值、方差和归一化的输出# 这里对第0个特征进行验证a = np.array([1,4,7])a_mean = a.mean()a_std = a.std()b = (a - a_mean) / a_stdprint('std {}, mean {}, \n output {}'.format(a_mean, a_std, b))# 建议读者对第1和第2个特征进行验证,观察numpy计算结果与paddle计算结果是否一致- 示例二: 当输入数据形状是时, 一般对应卷积层的输出,示例代码如下所示。
- 输入 x, [N, C, H, W]
- 输出 y, [N, C, H, W]
- 均值 ,[C, ]
- 方差 , [C, ]
- 缩放参数, [C, ]
- 平移参数, [C, ]
小窍门: 可能有读者会问: “BatchNorm里面不是还要对标准化之后的结果做仿射变换吗,怎么使用Numpy计算的结果与BatchNorm算子一致? ” 这是因为BatchNorm算子里面自动设置初始值,这时候仿射变换相当于是恒等变换。 在训练过程中这两个参数会不断的学习,这时仿射变换就会起作用。
# 输入数据形状是[N, C, H, W]时的batchnorm示例import numpy as npimport paddleimport paddle.fluid as fluidfrom paddle.fluid.dygraph.nn import BatchNorm# 设置随机数种子,这样可以保证每次运行结果一致np.random.seed(100)# 创建数据data = np.random.rand(2,3,3,3).astype('float32')# 使用BatchNorm计算归一化的输出with fluid.dygraph.guard(): # 输入数据维度[N, C, H, W],num_channels等于C bn = BatchNorm('bn', num_channels=3) x = fluid.dygraph.to_variable(data) y = bn(x) print('input of BatchNorm Layer: \n {}'.format(x.numpy())) print('output of BatchNorm Layer: \n {}'.format(y.numpy()))# 取出data中第0通道的数据,# 使用numpy计算均值、方差及归一化的输出a = data[:, 0, :, :]a_mean = a.mean()a_std = a.std()b = (a - a_mean) / a_stdprint('channel 0 of input data: \n {}'.format(a))print('std {}, mean {}, \n output: \n {}'.format(a_mean, a_std, b))# 提示:这里通过numpy计算出来的输出# 与BatchNorm算子的结果略有差别,# 因为在BatchNorm算子为了保证数值的稳定性,# 在分母里面加上了一个比较小的浮点数epsilon=1e-05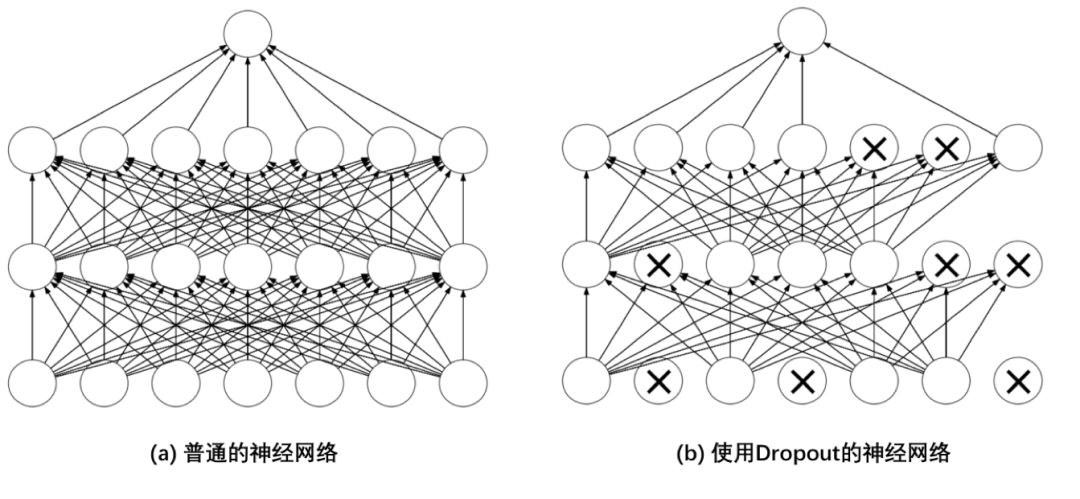
- 1downgrade_in_infer
- 2upscale_in_train
说明: 不同框架中dropout的默认处理方式可能不一样,读者可以查看其API以确认用的是哪种方式。
飞桨 dropout API 包含的主要参数如下:
- x,数据类型是Tensor,需要采用丢弃法进行操作的对象。
- dropout_prob,对x中元素进行丢弃的概率。
- is_test,是否运行在测试阶段,由于dropout在训练和测试阶段表现不一样,通过此参数控制其表现,默认值为False。
- dropout_implementation,丢弃法的实现方式,有'downgrade_in_infer'和'upscale_in_train'两种,具体情况请见上面的说明,默认是'downgrade_in_infer'。
# dropout操作import numpy as npimport paddleimport paddle.fluid as fluid# 设置随机数种子,这样可以保证每次运行结果一致np.random.seed(100)# 创建数据[N, C, H, W],一般对应卷积层的输出data1 = np.random.rand(2,3,3,3).astype('float32')# 创建数据[N, K],一般对应全连接层的输出data2 = np.arange(1,13).reshape([-1, 3]).astype('float32')# 使用dropout作用在输入数据上with fluid.dygraph.guard(): x1 = fluid.dygraph.to_variable(data1) out1_1 = fluid.layers.dropout(x1, dropout_prob=0.5, is_test=False) out1_2 = fluid.layers.dropout(x1, dropout_prob=0.5, is_test=True) x2 = fluid.dygraph.to_variable(data2) out2_1 = fluid.layers.dropout(x2, dropout_prob=0.5, \ dropout_implementation='upscale_in_train') out2_2 = fluid.layers.dropout(x2, dropout_prob=0.5, \ dropout_implementation='upscale_in_train', is_test=True) print('x1 {}, \n out1_1 \n {}, \n out1_2 \n {}'.format(data1, out1_1.numpy(), out1_2.numpy())) print('x2 {}, \n out2_1 \n {}, \n out2_2 \n {}'.format(data2, out2_1.numpy(), out2_2.numpy()))- 如何观看配套视频?如何代码实践?
- 学习过程中,有疑问怎么办?
- 如何学习更多内容?